In this article, we explore the process of creating a table in a file geodatabase using ArcGIS Pro.
To achieve this, we will utilize a notebook within ArcGIS Pro. Follow these steps to complete the task:
Open a new notebook in ArcGIS Pro.
Add the necessary libraries.
We will demonstrate two examples.
In the first case, we will utilize the built-in options - namely, arcpy and pandas.
- ExcelToTable
- Pandas
After presenting both methods, we will compare their pros and cons.
Let's begin with the Excel file that we aim to process, containing attribute information about roads.
The name of the Sheet is important to us. This name is a parameter that we set in the code. In our case, the name "Sheet" is the default. Let's review and the total number of records in excel it is 56602.

The first row of the Excel file contains the names of our new fields.
To successfully create a table in a relational database, these names must not contain special characters, be in English, and have no spaces.
Additionally, multiple cells should not be merged; otherwise, preprocessing is required before importing.
1. First way to import a table into a geographic database with ExcelToTable.
Let's examine the code, and later we'll break it down to understand each part.
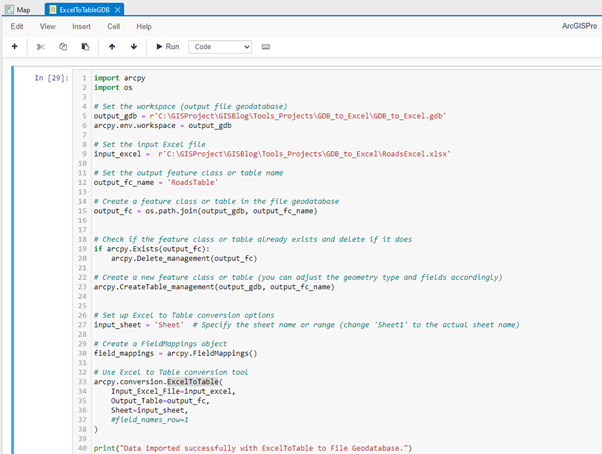
A message is printed after table processing is complete.
In ArcGIS Pro, we go to the Catalog tab and open Databases.
Let's check the result, we open the geographic database and look for the newly created table.
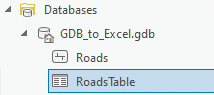
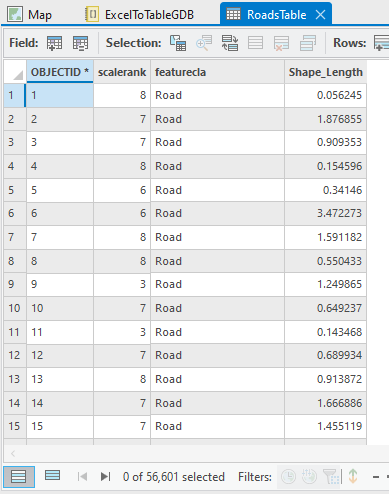
If you remember in the excel file we had 56602 rows. In the attribute table, we will always get one row at a time because this row contains the names of the fields we added.
At the beginning, it is necessary to specify the libraries that we will use. These are
import arcpy
import os
We'll pass in a path to the geodatabase and set it to be the workspace for the post-processing.
output_gdb = r'C:\GISProject\GISBlog\Tools_Projects\GDB_to_Excel\GDB_to_Excel.gdb'
arcpy.env.workspace = output_gdb
We add a path to an excel file
input_excel = r'C:\GISProject\GISBlog\Tools_Projects\GDB_to_Excel\RoadsExcel.xlsx'
We name the new table in file geodatabase
output_fc_name = 'RoadsTable'
We concatenate the name and path into one variable.
output_fc = os.path.join(output_gdb, output_fc_name)
Since we are doing the import repeatedly we want to check if a table with that name exists in the file geodatabase.
If there is such a table, we delete it.
if arcpy.Exists(output_fc):
arcpy.Delete_management(output_fc)
We create a table in gdb arcpy.CreateTable_management(output_gdb, output_fc_name)
We set the sheet name from excel as a parameter input_sheet = 'Sheet'
We create an object to store the names of our fields
field_mappings = arcpy.FieldMappings()
We convert our excel file into a table by specifying all the parameters, these are the name of the input file, a table from gdb, the name of the sheet from excel (if there are several sheets in excel, specify the correct one), we also have an additional parameter that we do not use in our case.
This is the field_names_row parameter, if the names of our fields are, for example, on the second row, and not on the first as it is by default, we can set the row number.
arcpy.conversion.ExcelToTable( Input_Excel_File=input_excel, Output_Table=output_fc, Sheet=input_sheet, #field_names_row=1 )
Let's take a look at the full code we used:
import arcpy
import os
# Set the workspace (output file geodatabase)
output_gdb =
r'C:\GISProject\GISBlog\Tools_Projects\GDB_to_Excel\GDB_to_Excel.gdb'
arcpy.env.workspace = output_gdb
# Set the input Excel file
input_excel =
r'C:\GISProject\GISBlog\Tools_Projects\GDB_to_Excel\RoadsExcel.xlsx'
# Set the output feature class or table name
output_fc_name = 'RoadsTable'
# Create a feature class or table in the file geodatabase
output_fc = os.path.join(output_gdb, output_fc_name)
# Check if the feature class or table already exists and delete if it does
if arcpy.Exists(output_fc):
arcpy.Delete_management(output_fc)
# Create a new feature class or table
arcpy.CreateTable_management(output_gdb, output_fc_name)
# Set up Excel to Table conversion options
input_sheet = 'Sheet'
# Specify the sheet name or range
# Create a FieldMappings object
field_mappings = arcpy.FieldMappings()
# Use Excel to Table conversion tool
arcpy.conversion.ExcelToTable(
Input_Excel_File=input_excel,
Output_Table=output_fc,
Sheet=input_sheet,
#field_names_row=1
)
print("Data imported successfully with ExcelToTable to File Geodatabase.")
2. Second way of importing a table into a geographic database with pd.read_excel and InsertCursor.
Let's see how this code works, and later we'll break it down to see how each part of it works.
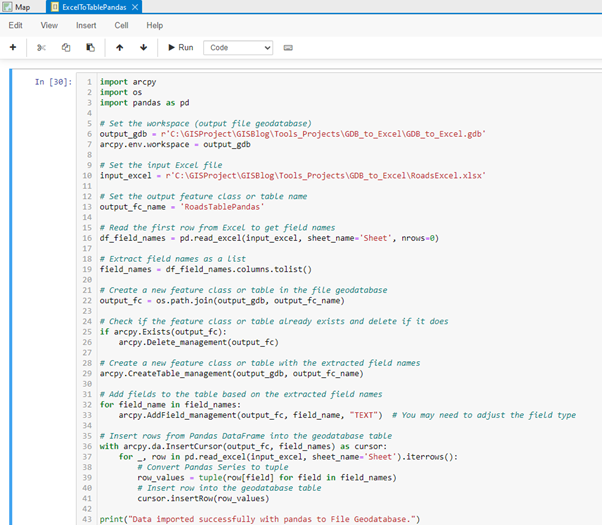
A successful code execution message is printed.
In ArcGIS Pro, we go to the Catalog tab and open Databases. Let's review the file geographic database to see if it contains the table we take from Excel.
Let's review the attribute table in ArcGIS Pro.
As you can see the result tables are exactly the same.
At the end of the article, we will compare the two methods.
At the beginning, it is necessary to specify the libraries that we will use.
These are
import arcpy
import os
import pandas as pd
We'll pass in a path to the geodatabase and set it to be the workspace for the post-processing
output_gdb = r'C:\GISProject\GISBlog\Tools_Projects\GDB_to_Excel\GDB_to_Excel.gdb'
arcpy.env.workspace = output_gdb
We add a path to an excel file
input_excel = r'C:\GISProject\GISBlog\Tools_Projects\GDB_to_Excel\RoadsExcel.xlsx'
We name the new table in file geodatabase
output_fc_name = 'RoadsTablePandas'
We concatenate the name and path into one variable
output_fc = os.path.join(output_gdb, output_fc_name)
Since we are doing the import repeatedly we want to check if a table with that name exists in the file geodatabase.
If there is such a table, we delete it.
if arcpy.Exists(output_fc):
arcpy.Delete_management(output_fc)
We create a table in gdb with
arcpy.CreateTable_management(output_gdb, output_fc_name)
We create an object to store the names of our fields
for field_name in field_names:
arcpy.AddField_management(output_fc, field_name, "TEXT")
We use arcpy's built-in crawl option, it's InsertCursor.
As parameters in this function we set the reading of the excel file
pd.read_excel(input_excel, sheet_name='Sheet') , this method looks for the name and the path to the excel as well as the name of the corresponding sheet.
We create a tuple with the names of the fields from excel which we will set as field names in the new table in gdb
row_values = tuple(row[field] for field in field_names)
And finally we load all the values from the rows in excel row by row into the new table cursor.insertRow(row_values).
with arcpy.da.InsertCursor(output_fc, field_names) as cursor:
for _, row in pd.read_excel(input_excel, sheet_name='Sheet').iterrows():
# Convert Pandas Series to tuple
row_values = tuple(row[field] for field in field_names)
# Insert row into the geodatabase table
cursor.insertRow(row_values)
import arcpy
import os
import pandas as pd
# Set the workspace (output file geodatabase)
output_gdb =
r'C:\GISProject\GISBlog\Tools_Projects\GDB_to_Excel\GDB_to_Excel.gdb'
arcpy.env.workspace = output_gdb
# Set the input Excel file
input_excel =
r'C:\GISProject\GISBlog\Tools_Projects\GDB_to_Excel\RoadsExcel.xlsx'
# Set the output feature class or table name
output_fc_name = 'RoadsTablePandas'
# Read the first row from Excel to get field names
df_field_names = pd.read_excel(input_excel, sheet_name='Sheet', nrows=0)
# Extract field names as a list
field_names = df_field_names.columns.tolist()
# Create a new feature class or table in the file geodatabase
output_fc = os.path.join(output_gdb, output_fc_name)
# Check if the feature class or table already exists and delete if it does
if arcpy.Exists(output_fc):
arcpy.Delete_management(output_fc)
# Create a new feature class or table with the extracted field names
arcpy.CreateTable_management(output_gdb, output_fc_name)
# Add fields to the table based on the extracted field names
for field_name in field_names:
arcpy.AddField_management(output_fc, field_name, "TEXT")
# You may need to adjust the field type
# Insert rows from Pandas DataFrame into the geodatabase table
with arcpy.da.InsertCursor(output_fc, field_names) as cursor:
for _, row in pd.read_excel(input_excel, sheet_name='Sheet').iterrows():
# Convert Pandas Series to tuple
row_values = tuple(row[field] for field in field_names)
# Insert row into the geodatabase table
cursor.insertRow(row_values)
print("Data imported successfully with pandas to File Geodatabase.")
Finally, let's compare the two methods:
Both methods, arcpy.conversion.ExcelToTable and using Pandas to insert rows into a geodatabase table, have their own pros and cons.
The choice between them depends on your specific requirements and preferences.
Here's a comparison:
ExcelToTable:
Pros:
Simplicity: The ExcelToTable tool is specifically designed for converting Excel files to tables in a geodatabase. It's a one-step process. Geodatabase Compatibility: Directly creates tables in a geodatabase, ensuring compatibility with the ArcGIS environment.
Cons: Limited Data Manipulation: Limited in terms of data manipulation or transformations during the import process. Field Mapping Limitations: May encounter limitations in field mapping, especially if your Excel file structure is complex.
Using Pandas:
Pros:
Flexibility: Pandas offers a high level of flexibility and control over the data manipulation process.
You can perform various data cleaning and transformation tasks before inserting into the geodatabase.
Extensive Data Analysis: Pandas is a powerful library for data analysis, providing tools for handling missing data, merging datasets, etc.
Pythonic Workflow: If you are already working with Python and have other data processing tasks, using Pandas fits well into a Pythonic workflow.
Cons:
Two-Step Process: Involves creating an empty table and then inserting rows, which might be seen as a two-step process.
Considerations:
Data Complexity: If your Excel data is straightforward and doesn't require extensive data cleaning or transformation, using arcpy.conversion.ExcelToTable might be more straightforward.
Data Analysis: If you need to perform complex data analysis or manipulation before inserting into the geodatabase, using Pandas provides a more flexible solution.
Workflow Integration: Consider how this data import fits into your overall workflow.
If you are already working extensively with Python and Pandas, it might be more convenient to use Pandas for consistency.
Geodatabase Structure: If you have a predefined geodatabase structure and want to ensure a direct mapping, arcpy.conversion.ExcelToTable can be more straightforward.
In summary, both methods are valid, and the choice depends on your specific needs and workflow preferences.
If you have a simple Excel-to-table conversion with minimal data manipulation, arcpy.conversion.
ExcelToTable might be more straightforward.
If you need more flexibility and control over the data processing, Pandas could be a better choice.
Thank you for your attention.
In future posts, we will explore how to use Python to check for classes, fields, and values in a file database.
Please consider subscribing to our newsletter.